Exploratory Data Visualization: Uber Trips Dataset
Introduction
One of my earliest projects. The goal of this project was to continue practicing Python for data analysis as I don’t use it in my current job. I looked for some clean and simple datasets and found this Kaggle dataset on Uber rides.
Analysis

The dataset contained trip details that originated from 2 pickup points: Airport and City. It was a pretty clean dataset, so I could do some exploratory analysis right away.
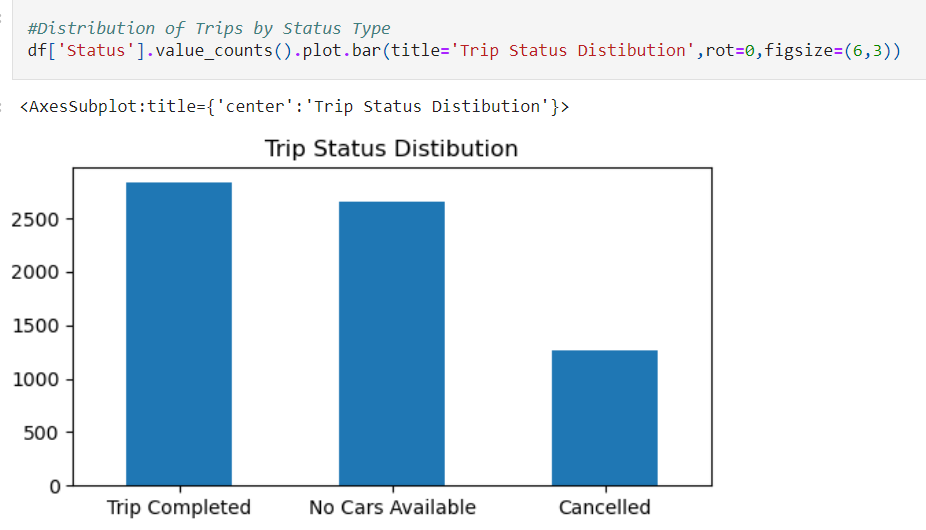
There were 3 outcomes to the trip. It could be completed with no issues, it could be canceled by either the rider or driver, or it could not be fulfilled due to there being no cars available. I created this plot to visualize trip outcomes.
I looked for any differences between pickup points next, thinking that maybe airport trips had a higher rate of “no cars available” due to extreme and highly localized demand. A quick visualization showed that my hunch was correct- almost 53% of airport trips resulted in “no cars available”!
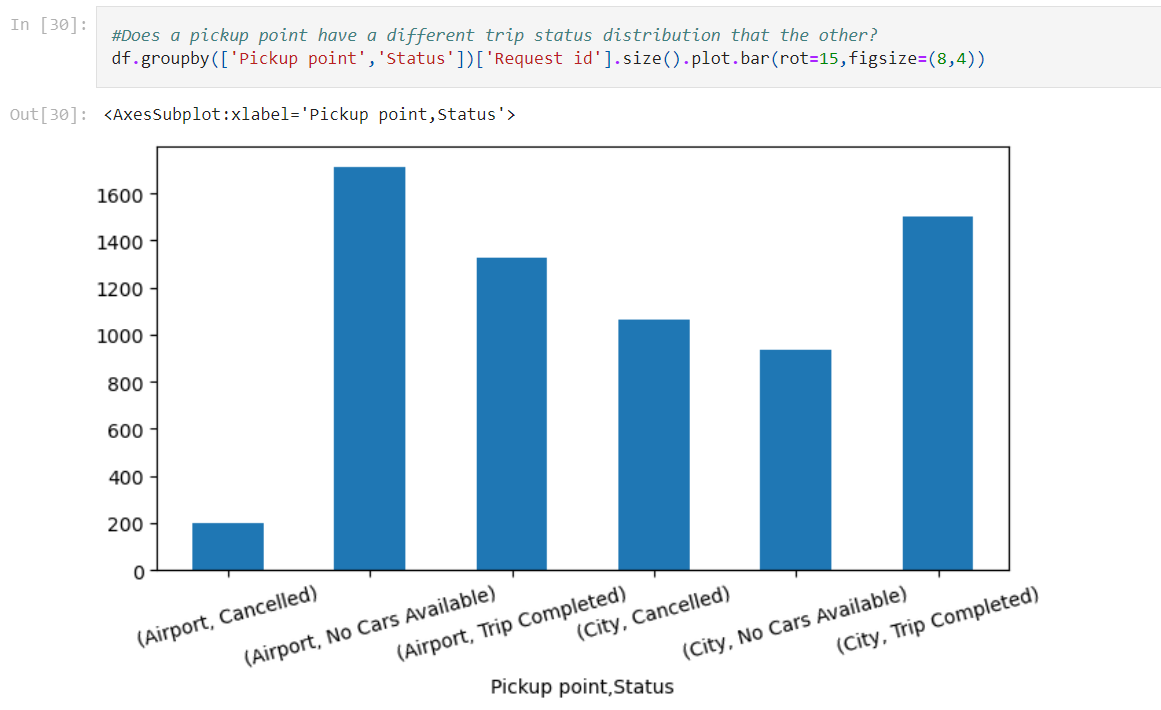
Trip completion rates between City (~43%) and Airport (~41%)weren’t too different, but it’s far more likely for an airport trip to be canceled due to a lack of available drivers in the area.
Another key difference between pickup points I wanted to check on was the duration of the trip. A quick check showed that the mean trip duration between both pickup points was very close.
I plotted the trip duration distribution to reveal more.

City trips have a higher amount of longer duration trips, which makes sense, as there is probably more traffic in the “city” (I imagine many are trips in dense downtown areas).
Conclusion
Overall, I was happy with this dataset as it was clean and easy for me to practice on, although I wish the city and airport would have been named to make it more interesting. Even this curiously vague dataset speaks to how annoying it is to use ride-share transportation out of the airport.
Link to Jupyter Notebook
